

云数据库HBase 场景应用浅析
/ 解决PB级大数据存储,千万级QPS读写访问 /
HBase的使用场景概览
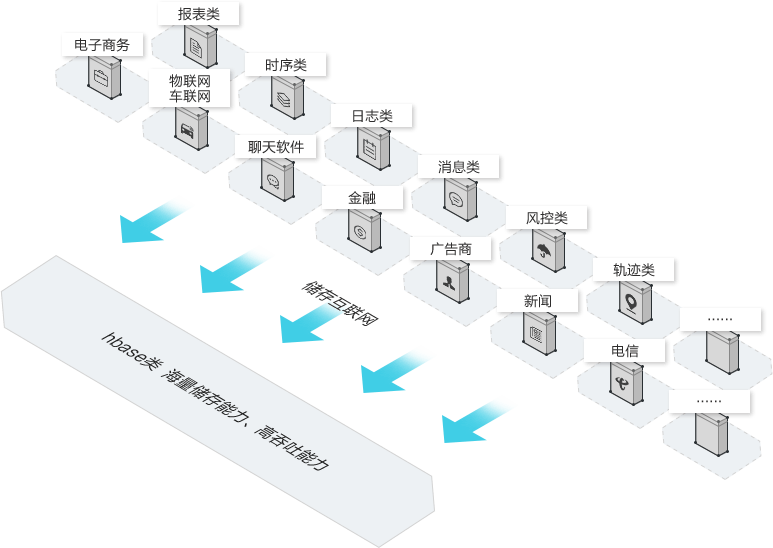
HBase在互联网领域有广泛的应用,比如:互联网的消息系统的存储、订单的存储、搜索原材料的存储、用户画像数据的存储等,除此之外,在其它领域也有非常多的应用。这得益于HBase海量的存储量及超高并发写入读取量。
阿里云 • 云数据库HBase是什么
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
阿里云 • 云数据库HBase在大数据分析中的地位
云HBase处于数据存储的位置,自带分析的功能
数据来源的途径有:
通过业务 ECS 直接写入到 云HBase之中,有一些消息中间件自带push功能,可以直接写入到HBase之中;有一些不行,需要拉取消息再转化处理后写入到HBase之中,通过流式系统,比如:SparkStreaming、Flink、Storm等流式引擎计算写入到云HBase之中,从离线同步数据到云HBase之中,一般为T+1同步,从关系型数据库同步数据到云HBase之中,可以做到实时同步在机器学习场景中,直接把云HBase作为存储。
云HBase的数据的去向:
云HBase自带Phoenix模块分析,支持百亿的毫秒级别分析,通过Spark等离线分析引擎分析,ECS业务端查询,如Scan一些数据,在客户端展示。

阿里云 • 云数据库HBase典型应用场景

基于LSM:
满足写入多,查询少的场景
查询效率高:
相邻数据储存一起、批量查询(scan)数据效率高
搭配使用:
ECS、LogService、 Spark、Hadoop

高并发高容量的数据应用:
满足高并发访问,数据快速入库出库,满足大屏、风控、搜索的储存的需求
大数据量:
支持千万的并发请求
高并发:
支持千万的并发请求
表特性:
稀疏表、动态列、TTL历史数据快速过期
搭配使用:
Hadoop、Spark、Flink、Storm

海量数据存储:
低成本大容量满足海量数据存储、支持高吞吐量实时入库及数据实时查询
大数据量:
支持TB-PB的存储空间
低成本:
支持云盘、oss、本地盘不同形态的实例最大程度降低用户成本
搭配使用:
ECS

实时分析:
满足千亿数据即时分析,实时返回结果
SQL访问:
简单、快速
访问速度:
倒排索引,加快速度 相邻数据存储一起scan数据效率高算子下沉到RegionServer过滤
搭配使用:
ECS
阿里云 • 云数据库HBase产品特点
- 内核在集团数百个集群使用、数百个业务、10000台左右规模 服务天猫双十一
- 跟踪开源社区改进,修复bug改进内核性能
- 多种增强功能,如支持 公网、内网 同时访问、支持OSS
- 运维主动推送升级,用户无感知
- 自动负载均衡
- 默认HA
- 对集群服务进程自动守护
- 单节点故障时可秒级故障迁移
- 独占资源,可靠稳定,不受其它用户干扰
- 支持在线增加节点,且可以平滑增加资源,如每个月增加1台
- 支持在线增加容量,且可以平滑增加资源,如存储量每月增加100g
- 计算量:从1k qps 到 5000w qps(满足大部分的需求)
- 存储量:从200g到1p (满足大部分的需求)
- 支持不同规格,不同场景的需求
- 支持独享、普通实例
- 支持SSD云盘、高效云盘
- 支持OSS存储(研发中)
- 支持本地实例(研发中)
- 15分钟内完成部署
- 可视化web控制台
- 全指标监控预警
- 修改配置等
- 支持通过 SQL 访问数据库数据
- 高效的二级索引方案让您查询数据更加便捷高效
阿里云 • 云数据库HBase产品推荐

 开发指南 >
开发指南 >
 FAQ >
FAQ >
 专家服务群 >
专家服务群 >















 中国站
中国站
 International
International
